SPQA: The AI-based Architecture That'll Replace Most Existing Software
AI is going to do a lot of interesting things in the coming months and years, thanks to the detonations following GPTs. But one of the most important changes will be the replacement of our existing software.
We used to adapt our businesses to the limitations of the software. In this model the software will adapt to how we do business.
AI-based applications will be completely different than those we have today. The new architecture will be a far more elegant, four-component structure based around GPTs: STATE, POLICY, QUESTIONS, and ACTION.
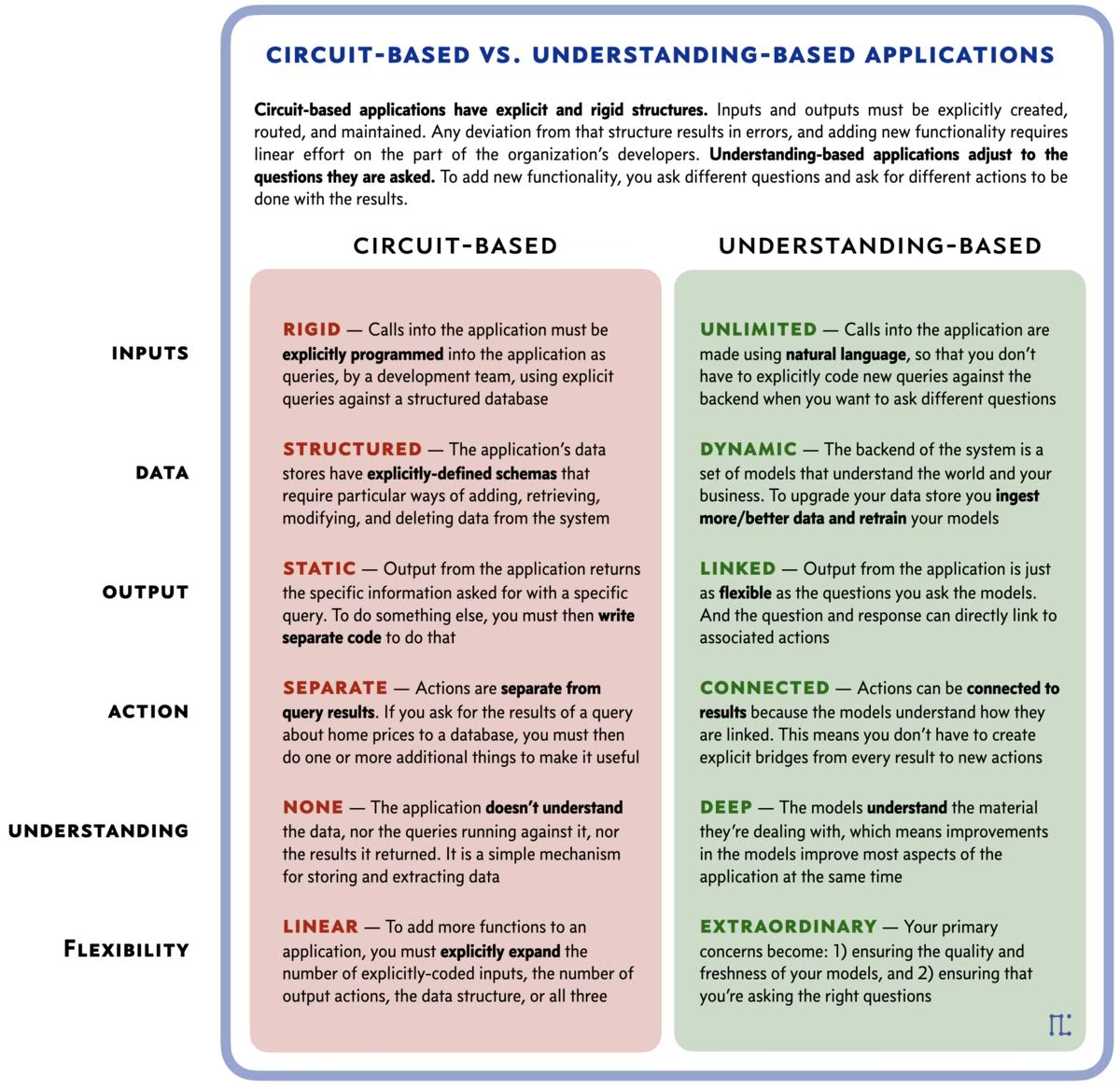
Fundamentally it's a transition from something like a Circuit-based architecture to an Understanding-based architecture.
Our current software is Circuit-based, meaning the applications have explicit and rigid structures like the etchings in a circuit board. Inputs and outputs must be explicitly created, routed, and maintained. Any deviation from that structure results in errors, and adding new functionality requires linear effort on the part of the organization's developers.
Circuit isn't the perfect metaphor, but it's descriptive enough.
New software will be Understanding-based. These applications will have nearly unlimited input because they're based on natural language sent to a system that actually understands what you're asking. Adding new functionality will be as simple as asking different questions and/or giving different commands.

The SPQA Architecture
(record screech sound)
"Nope! GPTs don't have true understanding…"
There are many who don't see what GPTs are doing as actual "understanding", but I address this argument in detail in my post about the substrate argument.
The short version is that both human brains and LLMs are black boxes that produce wondrous output through vast networks of small nodes—we just use different substrates. Any attempt to dismiss LLM understanding based solely on its substrate (transformer weights vs. biological neurons) is fundamentally flawed, as we have no idea how either system actually produces understanding.
For the purposes of this article, I'm using this definition of understanding: the ability to recognize patterns in existing knowledge and apply them to new situations and problems. And GPTs demonstrably do this.
Software that understands
It's difficult to grok the scope of the difference between our legacy software and software that understands.

I say "something like" because the exact winning implementations will be market-based and unpredictable.
Rather than try to fumble an explanation, let's take an example and think about how it'd be done today vs. in the very near future with something like an SPQA architecture.
A security program today
So let's say we have a biotech company called Splice based out of San Bruno, CA. They have 12,500 employees and they're getting a brand new CISO. She's asking for the team to immediately start building the following:
- Give me a list of our most critical applications from a business and risk standpoint
- Create a prioritized list of our top threats to them, and correlate that with what our security team is spending its time and money on
- Make recommendations for how to adjust our budget, headcount, OKRs, and project list to properly align to our actual threats
- Let's write up an adjusted security strategy using this new approach
- Define the top 5 KPIs we'll track to show progress towards our goals
- Build out the nested OKR structure that flows from that strategy given our organizational structure
- Create an updated presentation for the board describing the new approach
- Create a list of ways we're lacking from a compliance standpoint given the regulations we fall under
- Then create a full implementation plan broken out by the next four quarters
- Finally, write our first Quarterly Security Report, and keep that document updated
How many people will be needed to put this together? What seniority of people? And how long will it take?
If you have worked in security for any amount of time you'll know this is easily months of work, just for the first version. And it takes hundreds of hours to meet about, discuss, and maintain all of this as well.
Hell, there are many security organizations that spent years working on these things and still don't have satisfactory versions of them.
So—months of work to create it, and then hundreds of hours to maintain it using dozens of the best people in the security org who are spending a lot of their time on it.
A security program using SPQA
Let's see what it looks like in the new model.
It could be that POLICY becomes part of STATE in actual implementations, but smaller models will be needed to allow for more frequent changes.
Choose the base model — You start with the latest and greatest overall GPT model from OpenAI, Google, Meta, McKinsey, or whoever. Lots of companies will have one. Let's call it OpenAI's GPT-6. It already knows so incredibly much about security, biotech, project management, scheduling, meetings, budgets, incident response, and audit preparedness that you might be able to survive with it alone. But you need more personalized context.
Train your custom model — Then you train your custom model which is based on your own data, which will stack on top of GPT-6. This is all the stuff in the
STATEsection above. It's your company's telemetry and context:- Logs
- Docs
- Finances
- Chats
- Emails
- Meeting transcripts
- Everything
It's a small company and there are compression algorithms as part of the Custom Model Generation (CMG) product we use, so it's a total of 312TB of data. You train your custom model on that.
Train your policy model — Now you train another model that's all about your company's desires. The mission, the goals, your anti-goals, your challenges, your strategies. This is the guidance that comes from humans that we're using to steer the
ACTIONpart of the architecture. When we ask it to make stuff for us, and build out our plans, it'll do so using the guardrails captured here in thePOLICY.Tell the system to take the following actions — Now the models are combined. We have GPT-6, stacked with our
STATEmodel, also stacked with ourPOLICYmodel, and together they know us better than we know ourselves.So now we give it the same exact list of work we got from the CISO.
- Give me a list of our most critical applications from a business and risk standpoint
- Create a prioritized list of our top threats to them, and correlate that with what our security team is spending its time and money on
- Make recommendations for how to adjust our budget, headcount, OKRs, and project list to properly align to our actual threats
- Let's write up an adjusted security strategy using this new approach
- Define the top 5 KPIs we'll track to show progress towards our goals
- Build out the nested OKR structure that flows from that strategy given our organizational structure
- Create an updated presentation for the board describing the new approach
- Create a list of ways we're lacking from a compliance standpoint given the regulations we fall under
- Then create a full implementation plan broken out by the next four quarters
- Finally, write our first Quarterly Security Report, and keep that document updated
We'll still have to double-check models' output for the foreseeable future, as hallucination is a real thing this early in the game.
Let's say our new combined SPQA system is called Prima. Ask yourself two questions:
How long will it take it to create the first versions of all these, given everything it knows about the company?
How much time will it take to create updated versions every week, month, quarter, or year?
The answer is minutes. Not just for the initial creation, but for all updates going forward as well.
The only things it needs are:
- Up-to-date models using the latest data
- The right questions coming from the human leaders in the organization
In this case, we already have those questions in the list above.
Remember, Prima won't just come up with the direction, it'll also create all the artifacts:
- Every document
- Every OKR
- The QSR itself
- The strategy document
- The outline for the board presentation
- The auditor preparation documents
- Even the emails to stakeholders
That's additional hundreds of hours of work that would have been done by more junior team members throughout the organization.
So—we're talking about going from thousands of hours of work per quarter—spread across dozens of people—to maybe like 1% to 5% of that. In the new model the work will move to ensuring the POLICY is up to date, and that the QUESTIONS we're asking are the right ones.
Transforming software verticals
Sticking with security, since that's what I know best, imagine what SPQA will do to entire product spaces. How about Static Analysis?

Static Analysis in SPQA
In Static Analysis you're essentially taking input and asking two things:
- What's wrong?
- How do we fix it?
SPQA will crush all existing software that does that because it's understanding-based. So once it sufficiently grok's the problem via your STATE, and it understands what you're trying to do via your POLICY, it'll be able to do a lot more than just find code problems and fixes. It'll be able to do things like:
- Find the problem
- Show how to fix it in any language (coding or human)
- Write an on-the-fly tutorial on avoiding these bugs
- Write a rule in your tool's technology that would detect it
- Give you the fixed code
- Confirm that the code would work
Plus you'll be able to do far more insane things, like create multiple versions of code to see how they would all respond to the most common attacks, and then make recommendations based on those results.
Security software in general
Now let's zoom out to security software in general and do some quick hits on some of the most popular products.
Detection and response
- Who are the real attackers here?
- Who is dug in waiting for activation?
- Find the latest TTPs in our organization
- Write rules in our detection software that would find them
- Share those rules with our peers
- Pull their rules in and check against those as well
- Create a false parallel infrastructure that looks exactly like ours but is designed to catch attackers using the following criteria
- Automatically disable accounts, send notifications, reset tokens, etc. when you see successful attacks
- Watch for suspicious linked events, such as unknown phone calls followed by remote sessions followed by documentation review.
Basically, most of what you had to build by hand when you stand up a D&R function will be done for you because you have SPQA in place.
It natively understands what's suspicious. No more explicitly coding rules. Now you just add guidance to your POLICY model.
Attack surface management and bounty
- Pull all data about a company
- Find all its mergers and affiliations
- Find all documentation related to those things
- Make a list of all domains
- Run tools continuously to find all subdomains
- Open ports
- Applications on ports
- Constantly browse those sites using automation
- Send data to the SPQA model to find the most vulnerable spots
- Run automation against those spots
- Auto-submit high-quality reports that include POC code to bounty programs
- (if you're froggy) Submit the same reports to security@ to see if they'll pay you anyway
- Constantly discover our new surface
- Constantly monitor/scan and dump into a data lake (S3 bucket or equivalent)
- Constantly re-run
STATEmodel - Connect to alerting system and report-creation tooling
- Have the system optimize itself
Corporate security
- Monitor all activity for suspicious actions and actors
- Automatically detect and block and notify on those actions
- Ensure SaaS security is fully synched with corporate security policies (see
POLICY)
Vendor and supply chain security
Vendor and Supply Chain Security is going to be one of the most drastic and powerful disruptions from SPQA, just because of how impossiblehard the problem is currently.
- Make a list of all the vendors we have
- Consume every questionnaire we receive
- Find every place that the vendor's software touches in our infrastructure
- Find vulnerable components in those locations
- Make a prioritized list of the highest risks to various aspects of our company
- Recommend mitigations to lower the risk, staring with the most severe
- Create a list of alternative vendors who have similar capabilities but that wouldn't have these risks
- Create a migration plan to your top 3 selections
Today in any significant-sized organization, the above is nearly impossible. An SQPA-based application will spit this out in minutes. The entire thing. And same with every time the model(s) update.
We're talking about going from completely impossible…to minutes.
What's coming
Keep in mind this entire thing popped like 4 months ago, so this is still Day 0.
Those are just a few examples from cybersecurity. But this is coming to all software, starting basically a month ago. The main limitations right now are:
- The size limitations and software needed to create large custom models
- The speed and cost limitations of running updates for large organizations with tons of data
The first one is being solved already using tools like Langchain, but we'll soon have super-slick implementations for this. You'll basically have export options within all your software to send an export out, or stream out, all that tool's content. That's Splunk, Slack, GApps, O365, Salesforce, all your security software, all your HR software. Everything.
They'll all have near-realtime connectors sending out to your chosen SPQA product's STATE model.
We're likely to see STATE and POLICY broken into multiple sub-models that have the most essential and time-sensitive data in them so they can be updated as fast and inexpensively as possible.
For #2 that's just going to take time. OpenAI has already done some true magic on lowering the prices on this tech, but training custom models on hundreds of terrabytes of data will still be expensive and time-consuming. How much and how fast that drops is unknown.
How to get ready
Here's what I recommend for anyone who creates software today.
Start thinking about your business's first principles. Ask yourself very seriously what you provide, how it's different than competitor offerings, and what your company will look like when it becomes a set of APIs that aren't accessed by customers directly. Is it your interface that makes you special? Your data? Your insights? How do these change when all your competitors have equally powerful AI?
Start thinking about your business's moat. When all this hits fully, in the next 1-5 years, ask yourself what the difference is between you doing this, using your own custom models stacked on top of the massive LLMs, vs. someone like McKinsey walking in with The SolutionTM. It's 2026 and they're telling your customers that they can simply implement your business in 3-12 months by consuming your STATE and POLICY. Only they have some secret McKinsey sauce to add because they've seen so many customers. Does everyone end up running one of like three universal SPA frameworks?
Mind the Innovator's Dilemma. Just because this is inevitable doesn't mean you can drop everything and pivot. The question is—based on your current business, vertical, maturity, financial situation, etc.—how are you going to transition? Are you going to do so slowly, in place? Or do you stand up a separate division that starts fresh but takes resources from your legacy operation? Or perhaps some kind of hybrid. This is about to become a very important decision for every company out there.
Focus on the questions. When it becomes easy to give great answers, the most important thing will be the ability to ask the right questions. This new architecture will be unbelievably powerful, but you still need to define what a company is trying to do. Why do we even exist? What are our goals? Even more than your STATE, the content of your POLICY will become the most unique and identifying part of your business. It's what you're about, what you won't tolerate, and your definition of success.
My current mode is Analytical Optimism. I'm excited about what's about to happen, but can't help but be concerned by how fast it's moving.
See you out there.
Notes
- Thank you to Jolene Parish, Clint Gibler, Jason Haddix, and Saša Zdjelar for reading early versions of this essay and providing wonderful feedback.
- October 2, 2025 — Updated formatting throughout with consistent backticks for technical terms (
STATE,POLICY,ACTION,QUESTIONS), added asides and callouts for key points, and converted embedded lists to proper bullet points for improved readability.