How to Talk to AI
The real skill is clear thinking, not prompting or context

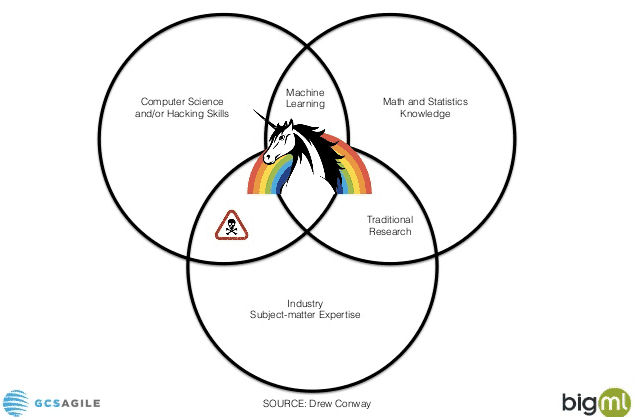
With the rise of interest in Machine Learning there are a couple of different perspectives out there around the similarities between it and Statistics. They generally fall into three camps:
"Machine Learning is identical to Statistics! They’re taught the same way, using the same books, using the same math, etc. You can use them interchangeably."
"Machine Learning is completely different and far superior to Statistics. It’s the next big things, and if you’re stuck doing Statistics you’re part of the past."
"Statistics is the real thing, and Machine Learning is just some newfangled name for it used by people who don’t understand the underlying concepts. It’s a fad, and I can’t wait for it to go away."
As a non-expert who’s just read a few books about both, my interpretation is that all three of these have truth to them, but that they’re essentially different approaches to similar problems that will ultimately merge.
Let’s explore where they currently seem to overlap and differ.
Most importantly, both Statistics and Machine Learning are used to help us improve human outcomes. They’re very often used to answer questions like:
How much better outcomes do we get if we walk vs. run as compared to being sedentary?
How does this income change as we adjust education?
Are vaccinations causing Autism Spectrum Disorder?
Is this an image of skin cancer?
Does this person have early signs of diabetes?
Both are heavily reliant on the fundamentals of mathematics and probability.
Both are heavily GIGO (garbage in, garbage out).
You can get both models and algorithms to tell you very attractive and misleading things if you design/implement them incorrectly.
Statistics is about more about inference, Machine Learning is more about prediction.
Statistics is more meticulous with the precious little data it gets to work with, Machine Learning is more about fail fast and move quickly using as much data as possible.
Statistics is most often applied to controlled studies to determine the effect of one or more particular variable on outcomes, where Machine Learning is applied more readily to datasets just to see if anything interesting shows up.
Statistics as a field is more conservative, with progress and findings shared in traditional journals, where Machine Learning types often freely publish their research before moving quickly onto the next thing.
Machine Learning types often don’t focus as much on being strong with mathematical fundamentals as Statistics types, and Statistics types are often stuck in a traditional "get off my lawn" mentality that impedes their ability to iterate quickly. Both could arguably improve by moving towards each other.
To me, however, the biggest difference between these two approaches is not in the subtleties of inference vs. prediction, or preferences in publishing. To me Machine Learning’s biggest advantage is self-improvement based on exposure to data.
That’s not a core feature of Statistics. Traditional Statistics is about having some fixed quantity of data, building models, and coming up with an answer. And then based on your findings you publish, discuss, and then iterate.
Slowly.
Machine Learning’s entire purpose is to self-teach, and I don’t think any of the other differences compare to that one.
The mathematical fundamentals of Statistics and Machine Learning are extremely similar.
The overal goal of improving human outcomes is extremely similar.
Statistics is more traditional, more fixed, and was not originally designed to have self-improving models.
Statistics is more academically formal and meticulous as a field, and uses smaller amounts of data, whereas Machine Learning is about doing what works, being willing to be imprecise if it’s effective, and being practical above all else using as much data as possible.
In my view, the disciplines might ultimately merge under the umbrella of data science, but for now Machine Learning’s core feature of self-improvement significantly sets it apart.
Data Mining is often included in the mix here. My opinion is that it’s best considered as a practical application of ML and/or Statistics, as opposed to its own separate thing.
This is a great Stack Exchange thread that talks through a number of perspectives. Link
I’m not an expert in either Statistics or ML, but what I am pretty good at is seeing differences between things. I think I’ve made these observations broad enough to be accurate while still being specific enough to be useful.
At some point the distinction starts to become quite semantic. It’s possible to define both ML and Statistics in ways that make them identical or non-overlapping. Ultimately usage will determine who’s right.
Coursera’s class on ML. Link
Image from Science Magazine