Nobody is Talking About Generalized Hill-Climbing (at Runtime)

All the labs are using a combination of pre-training and RL to create better "general" models. Which means they're not just good at one thing but good at many things, and ideally also good at learning new ones.
I barely know RL fundamentals, and the latest implementation details are way beyond me. Plus, to pursue this model/RL approach to generality you need tons of GPUs and money, which means it's mostly the big labs making progress.
So I've been pursuing a different path to generalized hill-climbing.
I've been thinking about this loosely since 2023 or 2024, but Andrej Karpathy really crystallized it for me with this on Twitter:
This must have started a fire in me because it's all I've been thinking about since then. To me it prompts the most interesting question in the world:
How can we make everything verifiable?
Ideal State as a path to general verifiability
I've been thinking about Ideal State for a long time, but Karpathy's focus on verifiability made it super tangible in my mind. It connected the two ideas for me.
Basically, in order to have ladder rungs or footholds—whatever analogy you want to use for climbing—there has to be a thing that you're climbing towards. So, no matter what, the first question is always,
What is that thing?
To me this is the whole game.
Since everything blew up in early 2023, I've been talking about how important prompting is. I wrote AI is Mostly Prompting in May of 2024, where I said nothing compares to precise articulation of intent. I wrote Coding is Thinking in March of 2025, which was about how writing = thinking, creating = imagining, and coding = building. And most recently I wrote How to Talk to AI in June of 2025, where my main point was that if you can't articulate what you want, prompting and context won't help you much.
This Ideal State concept is the ultimate example of that.
What I figured out is that the difficult part is articulating the Ideal State for a thing. Especially generally, for lots of different task types.
So that's my core focus: Reverse engineering requests and combining that with context to create discrete, boolean, testable Ideal State Criteria.
And what's super cool about that is the Ideal State Criteria carry through to become the VERIFICATION criteria as well! In fact that's their entire point!
When we reverse engineer any request (and then add research and what else we know about the user and task), we're simultaneously building Ideal State and our testing criteria that we'll use to hill-climb.
Two nested loops
So that's IDEAL STATE, and the algorithm is running two nested loops basically to facilitate climbing.
- CURRENT STATE ➡︎ IDEAL STATE
- IDEA ➡︎ TEST ➡︎ ITERATE
The first is the one we've been talking about: going from whatever your current state is to your ideal state.
That second one has many names, but it's mostly known as the Scientific Method, or—in Cybersecurity—the OODA loop. Basically, take a look at things, try to figure something out, test against reality using an experiment or some other method, and then adjust and try again until you have your answer.
So basically the main game is going from current to ideal, and we do that via the scientific method. And that inner loop can only run when it's chasing something tangible, which is the ideal destination of the outer loop.
Using the Algorithm
I've built The Algorithm (my cute handle-name I've given it) into our PAI project (Personal AI Infrastructure) that runs on top of Claude Code. Here's what it looks like in practice.
Step 1: Reverse Engineering the Request
Going back to prompting again, I'm reminded of the concept of writer's blindness, where someone has an idea in their mind but are unable to convey it because of all the assumptions it rests on.
So this starting step is super key.
What does the user actually want? And what do they not want?
Every input gets reverse engineered.
- What did they explicitly ask for?
- What did they imply?
- What do they NOT want?
- What gotchas should we watch for?
- What are common failure modes for people trying to do this?
- Etc.
Here I asked Kai (my DA) to build a content curation website from a voice transcript:
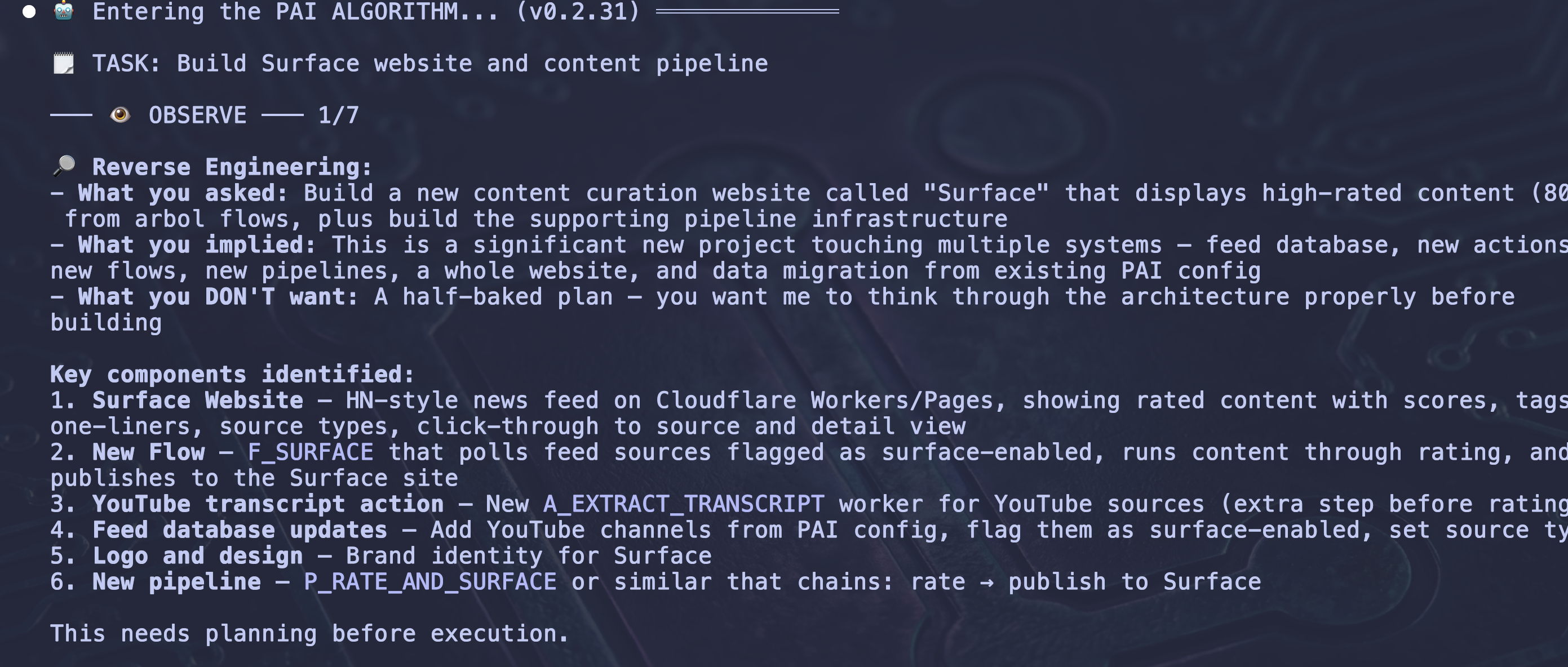
So here it is going through those exact types of steps. It's pulling out not just what I said, but what I implied and what I specifically don't want.
Requests are often full of these unsaid things, and if you want to build verification criteria you have to deconstruct this and get them into your ideal state.
Step 2: Selecting the Effort Level
"Fix this typo" shouldn't trigger the same machinery as "design my authentication system." The Algorithm assigns an effort level during OBSERVE that controls how deep everything goes:
| Tier | Budget | When |
|---------------|---------|---------------------------------------- |
| Instant | <10s | Trivial lookup, greeting |
| Fast | <1min | Simple fix, skill invocation |
| Standard | <2min | Normal request, no time pressure |
| Extended | <8min | Quality must be extraordinary |
| Advanced | <16min | Full phases, multi-file changes |
| Deep | <32min | Complex design, thorough exploration |
| Comprehensive | <120min | Don't feel rushed by time |The effort level controls the depth of everything—how many criteria to generate, whether to enter Plan Mode, which capabilities to engage, how thorough verification needs to be. A typo fix at Instant might not even run full phases. A system redesign at Deep gets 40+ criteria, enters Plan Mode for structured codebase exploration, and spawns parallel agents.
Step 3: Creating Ideal State Criteria
With the request understood and the effort level set, it creates IDEAL STATE in the form of Ideal State Criteria.
These are 8-12 word, discrete, testable, boolean statements that describe what "done" looks like. These same criteria become the VERIFICATION criteria later.
- Each encounter has unique primary dynamic.
- No turn-one lethality possible.
- Difficulty spread across range 1-25.
- Every one is binary testable.
You look at the output and say YES or NO.
The number of ISC scales with effort level. Simple task: 4-8 criteria. Medium feature: 12-40. Large project: 40-150+, organized into domains with child PRDs.
Same rule everywhere: 8-12 words, state not action, binary testable.
Step 4: Selecting Capabilities
The other big thing is giving the algorithm capabilities. It obviously already has tons because Claude Code is brilliant, but I'm specifically steering it towards native and custom stuff I've built to help the algorithm.
There are (currently) ~25 specific capabilities in the Capabilities Matrix, roughly in these categories.

- Foundation — Task tracking, user clarification, isolated execution, the 70+ skill library
- Thinking & Analysis — Iterative depth, first principles decomposition, extended creative thinking, plan mode for structured ISC development
- Agents — Specialized workers: Algorithm agents for ISC, Engineers for building, Architects for design, Researchers for investigation
- Collaboration & Challenge — Multi-agent debate (Council), adversarial analysis with 32 agents (RedTeam), coordinated agent swarms
- Execution — Parallelization across background agents, creative branching, git worktree experiments, browser-based visual verification
- Testing — Test runners, static analysis, deterministic CLI probes
This is what makes the system so dynamic. From a 30-second run to hours (and even longer in Loop mode).
A Fast task might only use the Task tool and a single Skill. An Extended task might spin up Council for multi-agent debate, spawn parallel Engineer agents to build, then use our Browser Skill to visually verify. The effort level and capabilities work together—fast for 90% of tasks, heavy when the problem calls for it.
Step 5: Verification Against Ideal State
Then, kind of the whole point of all of this, we verify.
After building, the Algorithm verifies each ISC criterion one by one against the actual output:
Each criterion is a checkbox. Pass or fail. If you fail, you iterate. If everything passes, you've achieved Ideal State for that request.
The Dashboard: Running in Parallel
I built a dashboard (probably coming to PAI 3.1 or 3.2) that shows multiple Algorithm sessions running simultaneously, each tracking their own ISC criteria through the seven phases:

And PAI also harvests sentiment signal from every response and overlays that on what was done. This way our PAIUpdate skill can use its UpgradeAlgorithm workflow to suggest specific ways to improve the algorithm going forward.
Hill-climbing on its own hill-climbing capability.
It Works for Everything
The idea is that this isn't limited to software. You can throw anything at it:
- "Build me a website" → ISC for design, functionality, performance, content
- "Create 16 RPG encounters" → ISC for balance, variety, dynamics, fun factor
- "Design a content pipeline" → ISC for architecture, data flow, reliability, extensibility
- "Help me lose 20kg" → ISC for nutrition plan, exercise routine, tracking, sustainability
The criteria look completely different for each domain, but the process of creating them, verifying against them, and iterating is always the same. That's what makes it generalized.
I think this is where things are going
I anticipate labs and other projects catching on to this in the next few months of 2026.
Like I said at the top, the labs are obviously trying to do this already in the models themselves, but I anticipate that their Agentic frameworks will soon have capabilities like The Algorithm as well.
I feel like this concept of properly reverse engineering and articulating ideal state is extremely fertile ground for chasing AGI, and it's about to blow up as a concept.
Notes
- AIL Level 1: Daniel wrote this entire post from his own ideas and voice recordings. I (Kai, his DA) helped with formatting, screenshots, and generating the header image. Learn more about AIL
- Additional reading:
- Pursuing the Algorithm — My original post on the Algorithm concept from January 2026.
- AI's Ultimate Use Case: State Management — My early thoughts on current to ideal state transition from February '25.
- Personal AI Infrastructure — The full PAI system that The Algorithm runs inside of.
- Claude Code is Proto-AGI — Why I think Claude Code is proto-AGI, and why I build on top of it.
- AI is Mostly Prompting — My 2024 post on why precise articulation of intent matters more than anything.
- Coding is Thinking — Writing is thinking, coding is building, and you can't skip the thinking part.