The Two Kinds of Privacy Loss

I like to think about our impending loss of privacy as two separate issues.
The first type is against the will of the victim and is caused by malice and/or negligence on the part of the entity with your data. This is where you trust your data to a company, and they sell that data to a number of unscrupulous third-parties just so they can make money. Alternatively, they’re so bad at data security that they leak it through sloppy transactions or allow it to be stolen through poor security hygiene.
The second kind is where the data is given willfully—by the user—to a number of trustworthy vendors, who then share it with other trustworthy vendors, who then share it some more, and the whole process continues for many years until your data ends up saturated throughout the internet.
Let’s call the first Involuntary, and the second Voluntary.
Importantly, both end up yielding the same result—your data spread across the internet like ashes in an ocean. Once the decision is made, either knowingly or unknowingly, to provide rich data to a series of data-centric companies, it’s a one-way function. It goes in, but can never come back.
But although the results are the same in both cases, I see these two situations very differently.
I believe that the loss of privacy is inevitable because the internet of things will be powered by personal data >, and we know from experience that people—especially young people—will gladly sacrifice privacy for functionality.
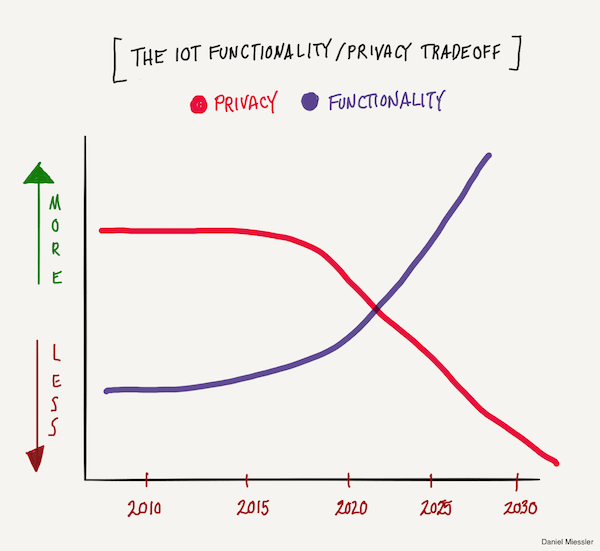
The internet of things, machine learning, and big data are all extreme cases of this tradeoff. The more data you give, the better peoples’ experiences with technology will get. Their assistants will anticipate their desires. Restaurants will bring your favorite dishes without asking. The world will basically be customized for each of us.
I believe the loss of privacy is inevitable, and I’m actually quite optimistic and forward-leaning on the issue. But I still want to avoid giving my data to companies with incentives misaligned to my own.
Companies with free services, for example, are not really free. Instead, the service itself is the hook, and the data that you provide the service is the actual product. This is true for Facebook and largely for Google as well.
So even though I know my data will inevitably be leaked due to the porous nature of the internet of things and machine learning powered services, I still want it to happen the slow way, through companies I trust to care for my data and only share it with other companies that have the same values or with my permission.
It’s not that I think this will stop the inevitable, but at least the inevitable will happen more on my own terms.
If you want to learn more about what I believe the Internet of Things will look like, you can read my book on the topic.
I guess the point here is that there’s a bit of cognitive dissonance here on my part, or at least it seems like there is sometimes. I am for digital assistants. I am for machine-learning-powered services. I am for an adaptive and personalized internet of things. And I believe that if you’re in cybersecurity you should accept the inevitability of the death of privacy, and work to make people comfortable in a post-privacy world.
But at the same time, I want to control that transition—using vendors that I trust—as much as possible.
Perhaps I’ll change my mind in one way or another, but that’s my current position.