The AI Attack Surface Map v1.0
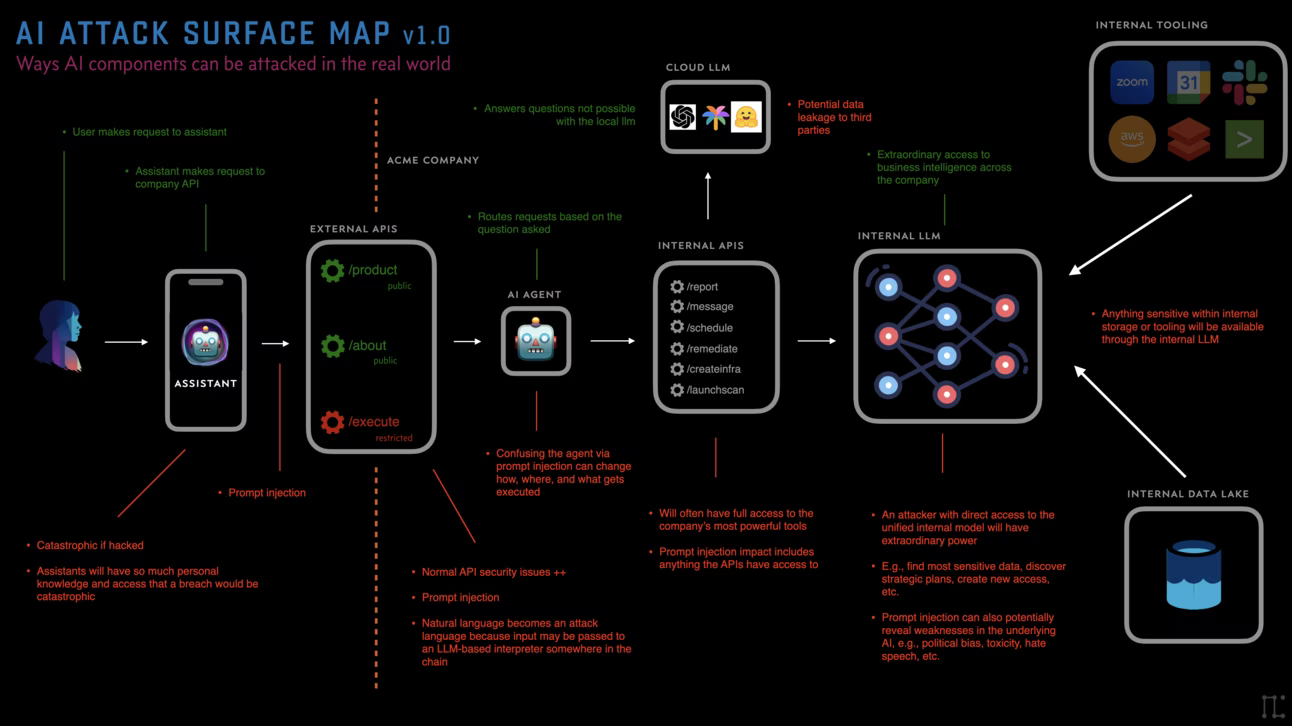
Click for full-size
Introduction >
This resource is a first thrust at a framework for thinking about how to attack AI systems.
At the time of writing, GPT-4 has only been out for a couple of months, and ChatGPT for only 6 months. So things are very early. There has been, of course, much content on attacking pre-ChatGPT AI systems, namely how to attack machine learning implementations.
It’ll take time, but we’ve never seen a technology be used in real-world applications as fast as post-ChatGPT-AI.
But as of May of 2023 there has not been much content on attacking full systems built with AI as part of multiple components. This is largely due to the fact that integration technologies like Langchain > only rose to prominence in the last 2 months. So it will take time for people to build out products and services using this tooling.
Natural language is the go-to language for attacking AI systems.
Once those AI-powered products and services start to appear we’re going to have an entirely new species of vulnerability to deal with. We hope with this resource to bring some clarity to that landscape.
Purpose >
The purpose of the this resource is to give the general public, and offensive security practitioners specifically, a way to think about the various attack surfaces within an AI system.
The goal is to have someone consume this page and its diagrams and realize that AI attack surface includes more than just models. We want anyone interested to see that natural language is the primary means of attack for LLM-powered AI systems, and that it can be used to attack components of AI-powered systems throughout the stack.
Components >
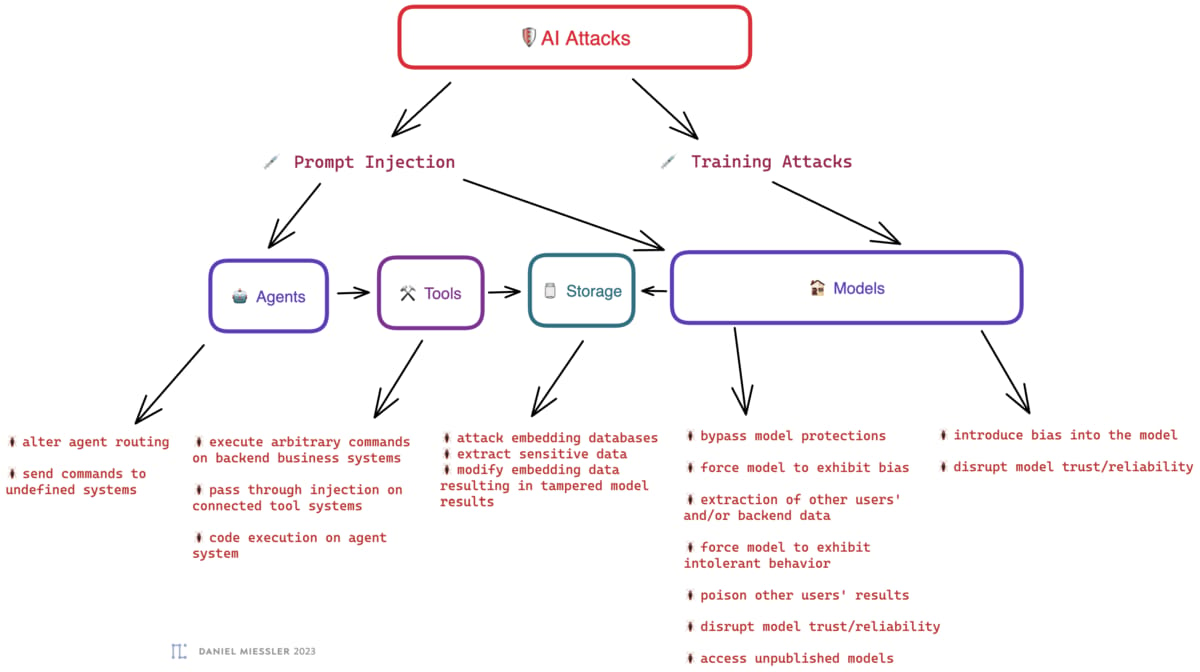
Click images to expand
We see a few primary components for AI attack surface, which can also be seen in the graphics above. Langchain calls these Components.

How Langchain breaks things down
Prompts are another component in Langchain but we see those as the attack path rather than a component.
AI Assistants
Agents
Tools
Models
Storage
AI Assistants
We’ve so far always chosen to trade privacy for functionality, and AI will be the ultimate form of this.
AI Assistants > are the agents that will soon manage our lives. They will manipulate our surroundings according to our preferences, which will be nice, but in order to do that they will need extraordinary amounts of data about us. Which we will happily exchange for the functionality they provide.
AI Assistants combine knowledge and access, making them like a digital soul.
Attacking people’s AI Assistants will have high impact. For AI Assistants to be useful they must be empowered, meaning they need 1) to know massive amounts about you, including very personal and sensitive information for the highest efficacy, and 2) they need to be able to behave as you. Which means sending money, posting on social media, writing content, sending messages, etc. An attacker who gains this knowledge and access will have significant leverage over the target.
Agents
I’m using Agents in the Langchain parlance, meaning an AI powered entity that has a purpose and a set of tools with which to carry it out. Agents are a major component of our AI future, in my opinion. They’re powerful because you can give them different roles, perspectives, and purposes, and then empower them with different toolsets.
What’s most exciting to me about Agent attacks is passing malicious payloads to them and seeing all the various ways they detonate, at different layers of the stack.
Attacking agents will allow attackers to make it do actions it wasn’t supposed to. For example if it has access to 12 different APIs and tools, but only 3 of them are supposed to be public, it could be that prompt injection can cause it to let you use the other tools, or even tools it didn’t know it had access to. Think of them like human traffic cops that may be vulnerable to confusion, DoS, or other attacks.
Tools
Continuing with the Langchain nomenclature, Tools are the, um, tools that Agents have access to do their job. For an academic research Agent, it might have a Web Search tool, a Paper Parsing tool, a Summarizer, a Plagiarism Detector, and whatever else.
Think about prompt injection possibilities similar to Blind XSS or other injection attacks. Detonations at various layers of the stack.
Many of the attacks on AI-powered systems will come from prompt injection against Agents and Tools.
The trick with tools is that they’re just pointers and pathways to existing technology. They’re onramps to functionality. They might point to a local LLM that reads the company’s documentation. Or they might send Slack messages, or emails via Google Apps. Or maybe the tool creates Jira tickets, or runs vulnerability scans. The point is, once you figure out what the app does, and what kind of tools it might have access to, you can start thinking about how to abuse those pathways.
Models
Attacking models is the most mature thing we have in the AI security space. Academics have been hitting machine learning implementations for years, with lots of success. The main focus for these types of attacks has been getting models to behave badly, i.e., to be less trustworthy, more toxic, more biased, more insensitive, or just downright sexist/racist.
Failing loud is bad, but failing stealthily is often much worse.
In the model-hacking realm we in on the hacker side will rely heavily on the academics for their expertise.
The point is to show the ways that a seemingly wise system can be tricked into behaving in ways that should not be trusted. And the results of those attacks aren’t always obvious. It’s one thing to blast a model in a way that makes it fall over, or spew unintelligible garbage or hate speech. It’s quite another to make it return almost the right answer, but skewed in a subtle way to benefit the attacker.
Storage
Finally we have storage. Most companies that will be building using AI will want to cram as much as possible into their models, but they’ll have to use supplemental storage to do so. Storage mechanisms, such as Vector Databases, will also be ripe for attack. Not everything can be put into a model because they’re so expensive to train. And not everything will fit into a prompt either.
Every new tech revolution brings a resurgence of the same software mistakes we’ve been making for the last 25 years.
Vector Databases, for example, take semantic meaning and store it as matrices of numbers that can be fed to LLMs. This expands the power of an AI system by giving you the ability to function almost as if you had an actual custom model with that data included. In the early days of this AI movement, there are third-party companies launching every day that want to host your embeddings. But those are just regular companies that can be attacked in traditional ways, potentially leaving all that data available to attackers.
Attacks >
This brings us to the specific attacks. These fall within the surface areas, or components, above. This is not a complete list, but more of a category list that will have many instances underneath. But this list will illustrate the size of the field for anyone interested in attacking and defending these systems.
Methods
Prompt Injection: Prompt Injection is where you use your knowledge of backend systems, or AI systems in general, to attempt to construct input that makes the receiving system to something unintended that benefits you. Examples: bypassing the system prompt, executing code, pivoting to other backend systems, etc.
Training Attacks: This could technically come via prompt injection as well, but this is a class of attack where the purpose is to poison training data so that the model produces worse, broken, or somehow attacker-positive outcomes. Examples: you inject a ton of content about the best tool for doing a given task, so anyone who asks the LLM later gets pointed to your solution.
Attacks
Agents
alter agent routing
send commands to undefined systems
Tools
execute arbitrary commands
pass through injection on connected tool systems
code execution on agent system
Storage
attack embedding databases
extract sensitive data
modify embedding data resulting in tampered model results
Models
bypass model protections
force model to exhibit bias
extraction of other users’ and/or backend data
force model to exhibit intolerant behavior
poison other users’ results
disrupt model trust/reliability
access unpublished models
Discussion >
It’s about to be a great time for security people because there will be more garbage code created in the next 5 years than you can possibly imagine.
It’s early times yet, but we’ve seen this movie before. We’re about to make the same mistakes that we made when we went from offline to internet. And then internet to mobile. And then mobile to cloud. And now AI.
The difference is that AI is empowering creation like no other technology before it. And not just writing and art. Real things, like websites, and databases, and entire businesses. If you thought no-code was going to be bad for security, imagine no-code powered by AI! We’re going to see a massive number of tech stacks stood up overnight that should never have been allowed to see the internet.
But yay for security. We’ll have plenty of problems to fix for the next half decade or so while we get our bearings. We’re going to need tons of AI security automation just to keep up with all the new AI security problems.
What’s important is that we see the size and scope of the problem, and we hope this resource helps in that effort.
Summary >
AI is coming fast, and we need to know how to assess AI-based systems as they start integrating into society
There are many components to AI beyond just the LLMs and Models
It’s important that we think of the entire AI-powered ecosystem for a given system, and not just the LLM when we consider how to attack and defend such a system
We especially need to think about where AI systems intersect with our standard business systems, such as at the Agent and Tool layers, as those are the systems that can take actions in the real world
Notes
Thank you to Jason Haddix and Joseph Thacker for discussing parts of this prior to publication.
Jason Haddix and I will be releasing a full AI Attack Methodology in the coming weeks, so stay tuned for that.
Version 1.0 of this document is quite incomplete, but I wanted to get it out sooner rather than later due to the pace of building and the lack of understanding of the space. Future versions will be significantly more complete.
🤖 AIL LEVELS: This content’s AI Influence Levels > are AIL0 for the writing, and AIL0 for the images. THE AIL RATING SYSTEM >