Introducing Amazon Curate (I Wish)
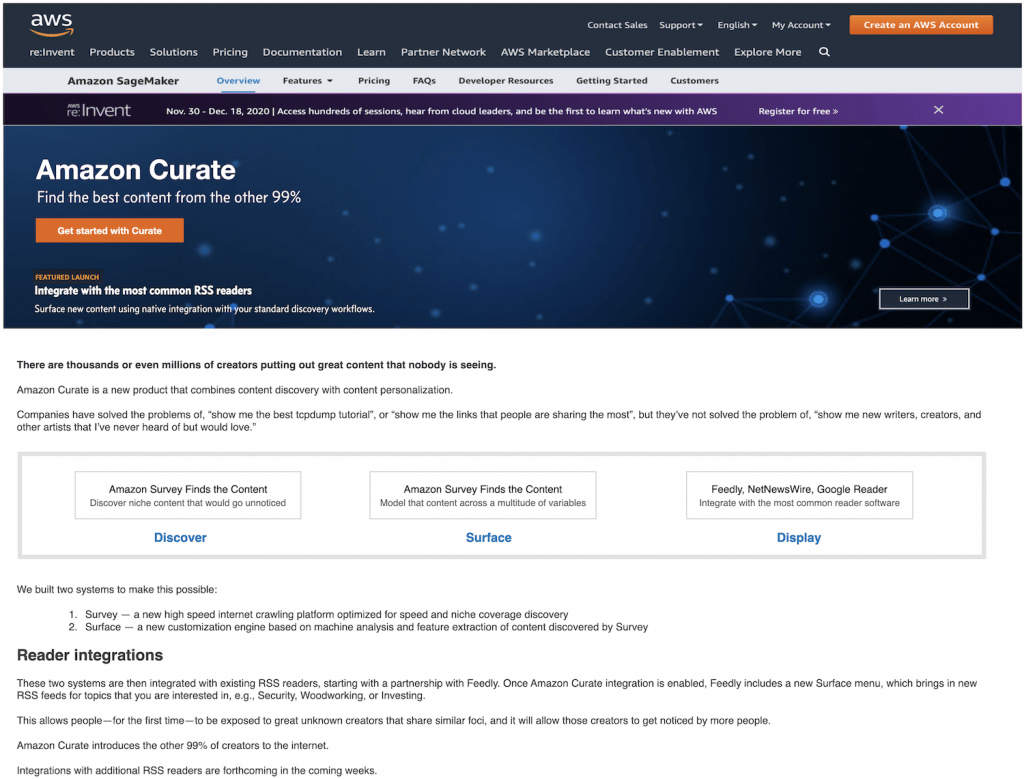 Click image for full size
Click image for full size
This isn't a real product, but I wish it were.
Announcing Amazon Curate
There are thousands or even millions of creators putting out great content that nobody is seeing.
Amazon Curate is a new product that combines content discovery with content personalization.
Companies have solved the problems of, "show me the best tcpdump tutorial", or "show me the links that people are sharing the most", but they've not solved the problem of, "show me new writers, creators, and other artists that I've never heard of but would love."
We built two systems to make this possible:
Survey — a new high speed internet crawling platform optimized for speed and niche coverage discovery
Surface — a new customization engine based on machine analysis and feature extraction of content discovered by Survey
These two systems are then integrated with existing RSS readers, starting with a partnership with Feedly. Once Amazon Curate integration is enabled, Feedly includes a new Surface menu, which brings in new RSS feeds for topics that you are interested in, e.g., Security, Woodworking, or Investing.
This allows people—for the first time—to be exposed to great unknown creators that share similar foci, and it will allow those creators to get noticed by more people.
Amazon Curate introduces the other 99% of creators to the internet.
Integrations with additional RSS readers are forthcoming in the coming weeks.
That's the product I've wanted for over a decade.
Discovery is a huge issue.
There's an argument that most of the good creators are already being seen because Google, Social Media, and word of mouth are finding the best stuff out there. But I don't buy that argument.
I have seen far too many examples of phenomenal content that sits on the internet, gets crawled by Google, and yet has no following.
These authors either don't know how, or care to, do self-promotion across various channels, so they either continue to write for nobody or they give up because they feel unseen.
But what if there was a "great contentness" rating that could be assigned by AI? I'm not an expert in the field, but it seems that we're getting pretty close to being able to use Unsupervised Learning on a given piece of content, find its various peculiarities, and then have a platform assign user-generated labels.
Then, when new content is discovered, it could go through the same process and get matched up with the preferences of a particular user.
This would be like combining Google, Netflix, and TikTok all into one engine.
So when you "like" content in Feedly, or you add it to your Read Later queue—or anything else that indicates positive sentiment—that is training data that says, "More of this please.", along with the subject matter of the existing content.
So if you like something about stock market trend analysis, the AI knows that's the topic, and it also extracts the features of the article itself.
Then it'd be able to tell you which content in a particular subject is likely to resonate with you, regardless of the current popularity of the author.
This is the content meritocracy that ML should be able to provide us. It shouldn't matter how popular someone is. They either create great content or they don't.
Let's surface the people who do.
Notes
Maybe more TikTok than Netflix because it'd be matching your particular tastes rather than looking at what similar people liked.
This unfortunately requires doing Unsupervised Learning feature extraction and then labeling of every piece of content in the system, including everything crawled and everything in Feedly (or whatever reader). That might be the resources bottleneck that has stopped this from happening before. But there has to be a shortcut to starting, even if we can't jump to ideal state.