A @TomNomNom Recon Tools Primer
There are recon tools, and there are recon tools.
@tomnomnom >—also called Tom Hudson—creates the latter.
I have great respect for large, multi-use suites like Burp >, Amass >, and Spiderfoot >, but I love tools with the Unix philosophy of doing one specific thing really well. I think this granular approach is especially useful in recon.
Related Talk: Mechanizing the >Methodology >
My talk on granular methodologies at Defcon’s Red Team Village in 2020
Basically:
Break your methodology into specific questions
Answer each question discretely
Create brutal combinations to accomplish your goals
Tom has built a serious following in the recon community by creating tools that enable this approach >, and I’ve seen enough people asking him for tutorials that I thought I’d make a quick primer on a few of my favorites: gf, httprobe, unfurl, meg, anew, and waybackurls.
Let’s get after it!
He writes his tools in Go as well, so they’re wicked fast.
A tour of Tom’s tools (nom nom nom ?)
It’s unrelated to actual grep, but has the same functionality.
gf (grep 4, grep for, grehp-four)

gf basically extends the standard Unix grep concept to include common things a bug hunter might look for. So if you’re hunting for some HTTP oriented PHP stuff, you can do this:
grep -HnrE ‘(\$_(POST|GET|COOKIE|REQUEST|SERVER|FILES)|php://(input|stdin))’ *
Or you an use gf and do it like this:
You can even have gf autocomplete your various patterns.
gf php-sources
And there are tons of pre-made examples >, including those for aws-keys, base64, cors, upload fields, and many more.
httprobe (HTTP probe, or HTTP Robe)

Pretty much all these tools are installed via go get -ugithub.com/tomnomnom/$repo.
httprobe answers the basic question of…
For the following domains, which ones are listening on web ports?
cat domains.txt | httprobe -p http:81 -p https:8443
web.acme.com web2.acme.com private.acme.com
Part of the UNIX Philosophy
What I love most about httprobe and most of Tom’s tools is that they are
truly Unixy. No need to run a standalone tool and obey its specific rules.
Any place you get a domain from you can just pipe directly in.
cat domains.txt | httprobe -p http:81 -p https:8443
web.acme.com web2.acme.com private.acme.com
Depends on the day I’m having. unfurl (un-FURL, or unfuck-YOU-ARE-EL)
unfurl breaks URLs into their discrete pieces so they can be referenced and
targeted in a granular manner.
echo https://sub.example.com/users?id=123&name=Sam | unfurl domains
sub.example.com
Isn’t that
freaking fucking
brilliant! Let’s do another, this time from a file.
You can pass -u to only get unique results. cat big-url-thingies.txt | unfurl paths
/users
And you can do this for domains, paths, keys, values, keypairs, and even
custom formats
>!
cat urls.txt | unfurl keypairs
You can then grep these for certain sensitive strings in a separate
operation.
id=123 name=Sam org=ExCo
meg (MÉHg)

meg combines domains and paths and makes requests at high speed in parallel. So if you have a list of domains that you hope are vulnerable, and a list of paths that would prove interesting (if they exist), you can use meg to request all of those paths on all of those sites.
If you just run meg it’ll request all paths in file ./paths on hosts in file ./hosts, and results are stored in ./out/index.
If you are only interested in certain response codes, you can use the --savestatus switch, like so:
meg –savestatus 200 /robots.txt
Because we passed the robots.txt path on the command line, this command will only look for that path in all hosts instead of looking at ./paths.
I love automated workflows that go off and find me interesting things to poke at manually.
Why is this command cool? Well, for lots of reasons, but the first thing that popped into my mind was using it in conjunction with my Robots Disallowed > project, which captures the most common disallowed paths on the internet. I have a curated > file in there that includes potentially sensitive paths.
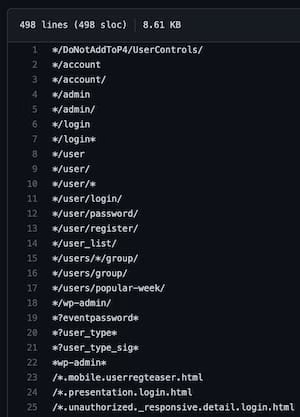
Some top results from curated.txt
So for any given set of URLs that are in your scope you could keep a handy copy of head -100 curated.txt for your ./paths file, and combine that with --savestatus 200 to pre-seed some juicy targets during a test.
anew (uh-NEW)

anew adds the contents of an input stream to the output—but only if it’s not already there. Do you know how epically awesome this is? Much.
I hereby nominate this for being included by default in Linux.
So let’s say you’ve collected a massive list of vulnerable paths on a bunch of a target’s websites, and you think you found some more using a different process. Well, instead of doing multiple steps of cat, sort, and uniq, you can instead just send the new stuff to the existing stuff.
cat new-cool-shit.txt | anew old-cool-shit.txt
Now, old-cool-shit.txt has both the new and old stuff you wanted, with no duplicates!
waybackurls (WAY-back-you-are-ehls, WAYback-U-Are-els, wayback-Earl’s)

Or at least the ones that wayback saw.
waybackurls goes and finds all the URLs that have ever been part of a target domain. This is super useful for finding stuff that might no longer be indexed, or that might not even exist anymore but could show you something about how the creator/admin thinks.
cat domains.txt | waybackurls > wayback-urls.txt
Or if you wanted to be cool, you could use anew from above to add those to your existing URLs.
One example of the power of chaining.
cat domains.txt | waybackurls | anew urls.txt
Summary
Discret, Unixy tools are powerful because they can be combined in extraordinary ways. This is just a quick look at a few of Tom’s tools, which you can find more of here >.
gf lets you easily grep for security-sensitive stuff. Link >
httprobe checks for webservers on domains. Link >
unfurl breaks URLs into their bits and pieces. Link >
meg makes combined domain/path requests. Link >
anew adds input to an output, if it’s new. Link >
waybackurls finds archived URLs for a domain. Link >
Hat tip to @tomnomnom > for the great work, and I hope he becomes an example for others to create small, useful utilities that can become part of complex workflows.
Notes
You can mostly ignore the pronounciation bits. I was just being silly.
Half of these tools should seriously be included in major Linux distros. And I mean, like, pre-installed in /usr/bin/. Who do I need to talk to? Somebody find me a manager.