Reverse Threat Modeling for Pursuing Attribution
I was thinking about the recent Twitter hack the other day and thought of a simple technique for evaluating possible threat actors of information warfare campaigns.
I’m sure this is obvious to true practitioners in this space, and that what I’m describing probably has a formal name and more robust methodology, but I think this is useful just as a quick shortcut for non-experts.
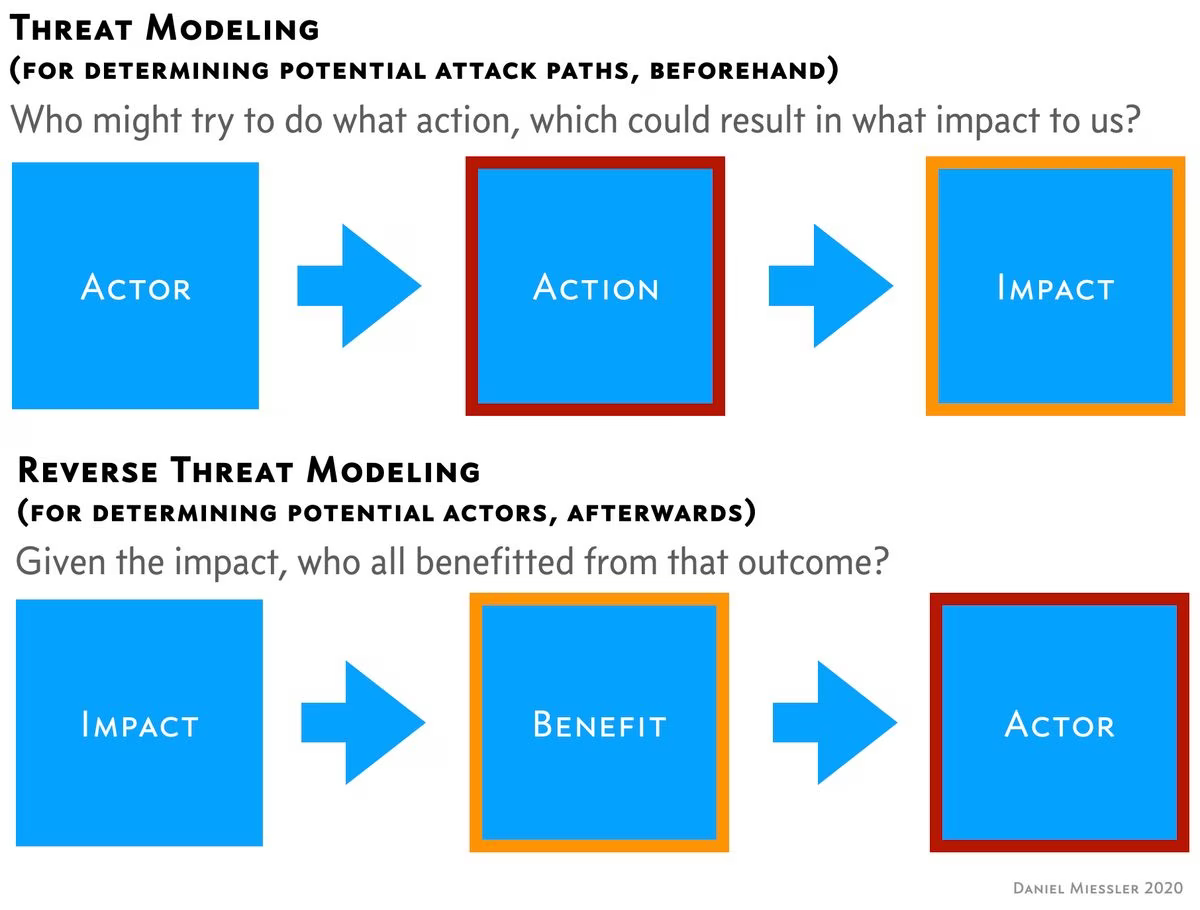
With Threat Modeling we are looking at potential situations before an attack has occurred, and the focus is on what technique may be used.
When we look at impacts that we know already happened (like the Twitter hack), one of the questions is—of course—how did it happen, but the bigger question is often who.
I think it helps to simply reverse the process into:
Impact –> Benefit –> Actor
Or, in other words:
Spend time creating a list of second and third-order effects of the action.
List all the different people and organizations that would benefit from those effects.
Narrow that list down by who had the capability to do it, and doesn’t have other constraints that take it off the list.
What are you left with?
To be clear, I don’t think this always gets you an answer. Well I’m sure it doesn’t, otherwise attribution would be easy.
But it does get us thinking about the problem in the right way. And that’s usually a good start.