The Real Difference Between a URL and a URI
A URL is a subtype of URI that includes a protocol, like FTP or HTTP
Updated: October 10, 2023
URI vs. URL is one of the most famous geek battles, but it’s simpler than people make it out to be.
Both URLs and URIs are ways of finding something online
A URI can be a name by itself, OR a name with a protocol
A URL is a subtype of URI with both a resource and a protocol
In other words, all URLs are URIs, but not all URIs are URLs
NOTE: URI stands for Universal Resource Identifier, and URL stands for Universal Resource Locator.
If we were trying to find someone in the real world, a URI could be a name of a person, or a name combined with their address.
But a URL is always a name combined with an address (resource + protocol).
So which is more correct?
What we really want to know is when someone gives a website name or whatever—should we call that a URI or a URL?
URI Types and Subtypes
My answer is that it depends if someone includes the protocol or not, or if the protocol is implied. If it’s either included or implied, then URL is probably most correct because it’s most specific.
It’s like, if you’re in a bird store and someone asks what kind this one is, you can say it’s a bird—and you’d be correct—but you’d be more correct if you said it was a parakeet.
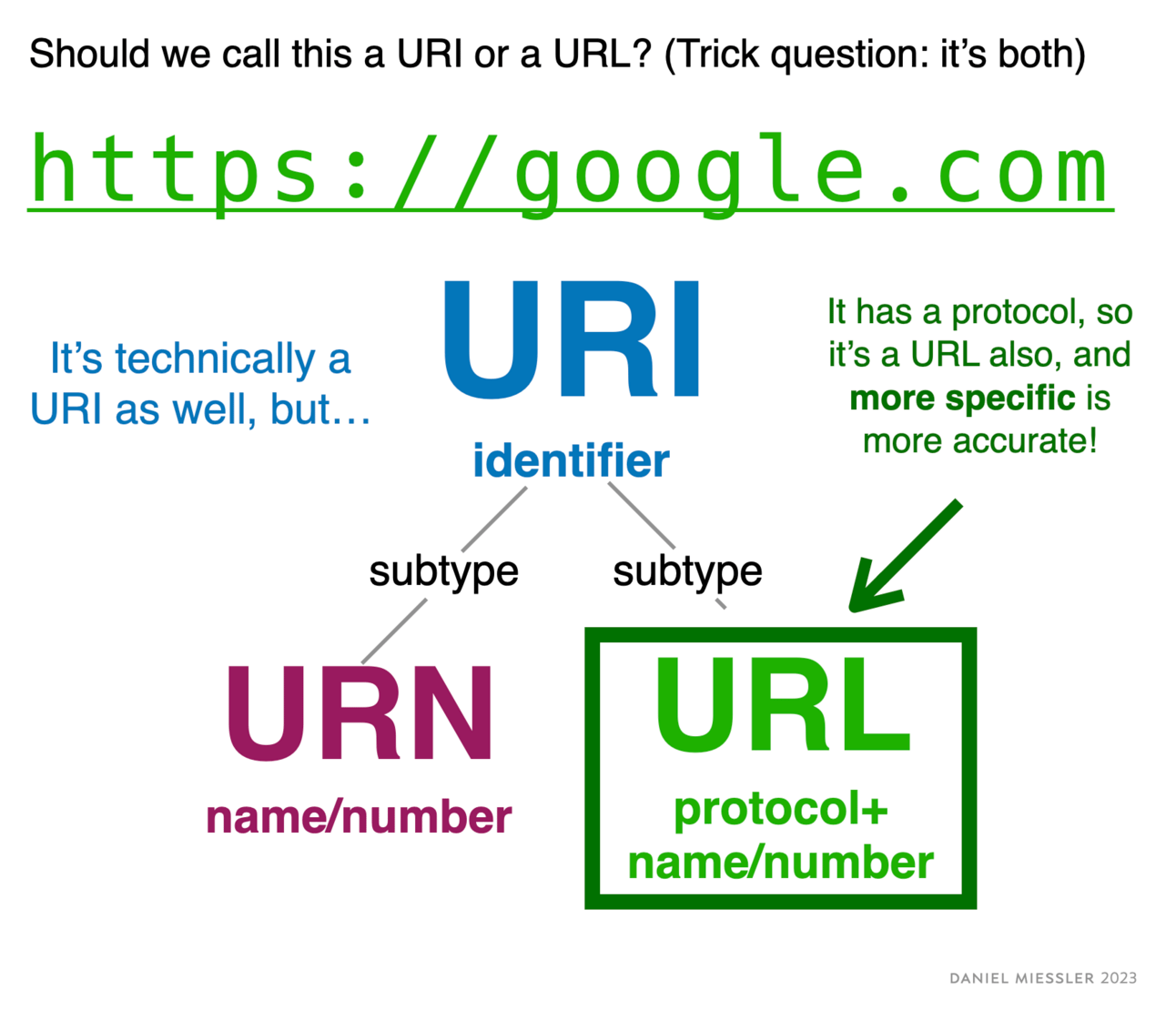
It’s the same with URI and URL. https://google.com > is technically a URI, but it’s also a URL, so URL is the best way to refer to it.
NOTE: Some people just want to say URI because it trips people up and it’s still technically correct.
google.com …is a URI because it is only the name of a resource
https://google.com …is a URL because it’s both the name and how to get there
Those are the basics, but you can get more technical detail below about the difference between URIs and URLs, as well as URNs.
—
URIs, URLs, and URNs
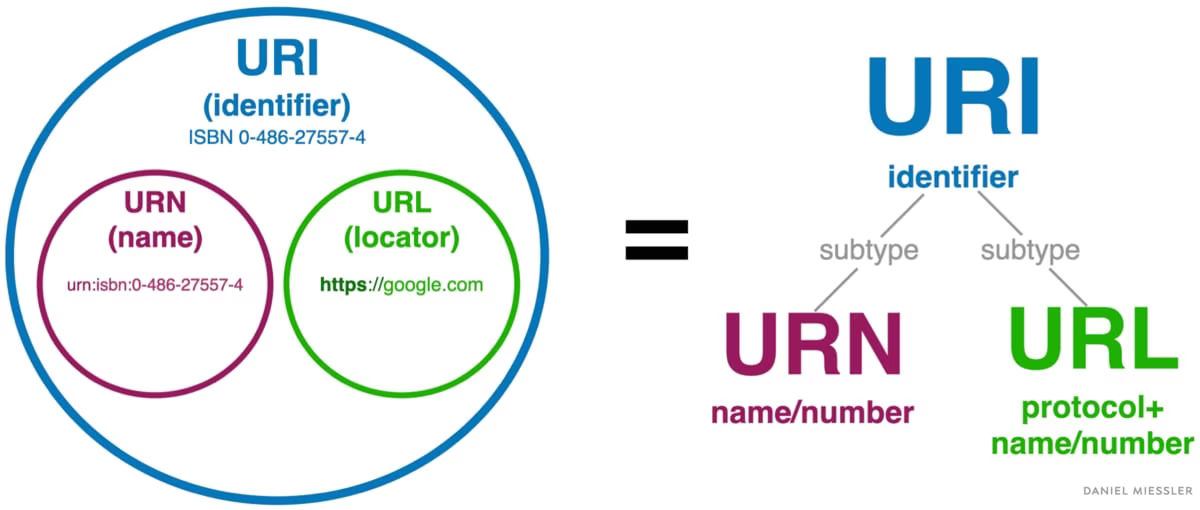
A Uniform Resource Identifier (URI) is a string of characters that uniquely identify a name or a resource on the internet. A URI identifies a resource by name, location, or both. URIs have two specializations known as Uniform Resource Locator (URL), and Uniform Resource Name (URN).
A Uniform Resource Locator (URL) is a type of URI that specifies not only a resource, but how to reach it on the internet—like http://, ftp://, or mailto://.
A Uniform Resource Name (URN) is a type of URI that uses the specific naming scheme of urn:—like urn:isbn:0-486-27557-4 or urn:isbn:0-395-36341-1.
So a URI or URN is like your name, and a URL is a specific subtype of URI that’s like your name combined with your address.
All URLs are URIs, but not all URIs are URLs.
We’ve learned above that URIs include both URNs and URLs, but let’s break that into more detail.
A URI is an identifier of a specific resource. Examples: Books, Documents
A URL is special type of identifier that also tells you how to access it. Examples: HTTP, FTP, MAILTO
If the protocol (https, ftp, etc.) is either present or implied for a domain, you should call it a URL—even though it’s also a URI.
In other words, in 99% of everyday cases, you should use URL instead of URI because both are technically true but URL is more specific!
URL Structures
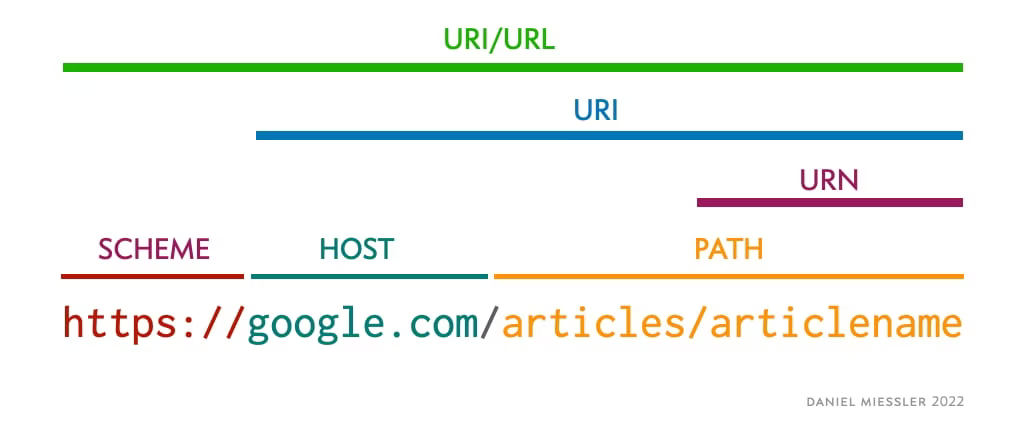
URLs have their own specific structure as well. In that structure you have the following components:
The Scheme, which is the protocol that you’re using to interact.
The Authority, which is the target you’re accessing. This breaks down into userinfo, host, and port.
The Path, which is the resource you’re requesting on the host.
The Query, which are the parameters being used within the web application.
The Fragment, which is the target to jump to within a given page.

Schemes can include: HTTP, HTTPS, FTP, MAILTO, IRC, FILE, etc. HTTP and HTTPS are usually used to reach internet resources, but they can point to local (on-network or on-computer) resources as well.
The FILE scheme refers to a file located on the local computer, and it looks for the file at the path that’s provided. The host can also include a port designation that overrides the default port for the specified protocol. For example:
https://google.com
…will go to the host google.com on port 443 because 443 is the default port for HTTPs. But if you specify the port like so:
https://google.com:9023
…the client will attempt to connect to connect to port 9023 using the HTTPs protocol instead.
Finally, URLs also have query parameters and fragment identifiers.

Query parameters indicate an argument being passed into a web application, such as a search function for a webpage, like:
https://google.com/search?s=bing
This would search for the word "bing" on a function called search on Google.
Fragments allow you to jump to a specific part of the page from the URL, like so:
https://google.com/results.html#worse
This would jump to a hyperlink on the page labeled "worse" on the page named results.html.
Quizing Some Examples
Ok, let’s look at some examples and see if you can answer the questions.
Is this a URI, URL, or a URN?
www.google.com
Answer: It’s an incomplete URL because it doesn’t have a protocol (although you can argue that it can be implied). As for the structure, if this were a URL it would only be the host portion because it lacks a scheme and a path.
Is this a URI, URL, or a URN?
userstats.html
Answer: This looks to be a resource within a URL, but since it doesn’t seem to be a unique resource or prefaced by the urn: prefix, it is not a formal URN. So it is neither a URN, URL, or URI.
RFC Confusion
A deeper explanation (let’s get technical)
Let me warn you: this is one of the most common NerdFights in tech history, and that’s saying a lot.
One obstacle to getting to the bottom of things is that the relevant RFCs are extremely dense, confusing, and even contradictory. For example, RFC 3986 says a URI can be a name, locator, or both…
A URI can be further classified as a locator, a name, or both. The term "Uniform Resource Locator" (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network "location").
RFC 3986, Section 1.1.3 >But just a little further down that same RFC says…
The URI itself only provides identification; access to the resource is neither guaranteed nor implied by the presence of a URI.
RFC 3986, Section 1.2.2 >And then, if you’re not yet completely confused, it also says…
Each URI begins with a scheme name, as defined in Section 3.1, that refers to a specification for assigning identifiers within that scheme.
RFC 3986, Section 1.1.1 >And it goes on to give examples >:
Notice how they all their examples have schemes.
ftp://ftp.is.co.za/rfc/rfc1808.txt >
http://www.ietf.org/rfc/rfc2396.txt >
ldap://[2001:db8::7]/c=GB?objectClass?one
news:comp.infosystems.www.servers.unix
tel:+1-816-555-1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
RFC shennanigansWait…what?
These three contradictions are the source of this entire long-lived debate.
The same RFC just told us that a URI can be a name, a locator, or both—but a URI only provides identification, and a way to access isn’t guaranteed or implied—oh and also each URI begins with a scheme name (which in many cases tells you exactly how to access the resource).
It’s no wonder everyone is confused!
The reason the internet’s been fighting about this for over a decade is that the RFC is poorly written.
Salvaging practical rules from all this
Being the top search result for this topic means I have the conversation a lot.
Ok, so given the fact that the RFC adds to confusion rather than eliminating it, what—if anything—can we use from them?
In the vein of language being here for communication rather than pedantry, here are my own practical interpretations of the RFCs that will hopefully synchronize people and result in fewer swordfights.
All butterflies fly, but not everything that flies is a butterfly.
A Uniform Resource Identifier (URI) provides a simple and extensible means for identifying a resource (straight from RFC 3986). It’s just an identifier; don’t overthink it.
For most debates about this that matter, URI is the superset, so the question is just whether a given URI is formally a URL or not. All URLs are URIs, but not all URIs are URLs. In general, if you see http(s)://, it’s a URL.
URIs technically do require a scheme (see above), but the RFC also says they can be a name, locator, or both, so YOLO! My advice for anyone saying URIs do or do not require a scheme is to show them this article, because it’s the only thing I know of that highlights the contradictions in the RFC.
Fragments likefile.htmactually are not URNs, because URNs are required to use a special notation > with urn: in the beginning.
A little-known section of RFC 3986 actually speaks directly to the religious part of the argument, and seems to say we should say URI instead of URL.
RFC 3986 is from 2005, so presumably they’re saying URI is the preferred term after that point.
Future specifications and related documentation should use the general term "URI" rather than the more restrictive terms "URL" and "URN"
RFC 3986, Section 1.1.3 >So that’s support for the "URI" denomination, but in my opinion it’s even more support for those who say, "stop looking for the answers in 15-year-old RFCs".
It’s like another widely-read text in this way.
There’s just so much contradictory content that there’s partial backing for multiple conclusions.
Summary
What a mess. Here’s the TL;DR >…
The RFCs are ancient, poorly written, and not worth debating until they’re updated.
A URI is an identifier.
A URL is an identifier that tells you how to get to it.
Use the term that is best understood by the recipient.
I’d welcome a new version of the RFC that simplifies and clarifies the distinction, with modern examples.
These RFCs were written a very long time ago, and they’re written with the academic weakness of not being optimized for reading.
The best thing I can possibly tell you about this debate is not to over-index on it. I’ve not once in 20 years seen a situation where the confusion between URI or URL actually mattered.
The irony is that RFCs are supposed to remove confusion, not add to it.
So while there is some direct support that "URI" is preferred by the RFCs, and "URL" seems most accurate for full addresses with http(s) schemes (because it’s most specific), I’ve chosen to prioritize the Principle of Communication Clarity higher than that of pedantic nuance.
It’s taken me a long time to get to this point.
As a result, I personally use "URL" in most cases because it’s least likely to cause confusion, but if I hear someone use "URI" I’ll often switch immediately to using that instead.
NOTES
Feb 20, 2022 — Added additional sections and more in-depth explanations of differences in URLs, URIs, and URNs.
Jan 16, 2022 — Updated for brevity, legibility, and clarity.
May 3, 2019 — I’ve done a major update to the article, including correcting some errors I had in previous versions. Namely, I had fragments such as file.html shown as a URN, which is not right. This version of the article is the best version, especially since it fully explores the conflicting language within the RFC and how little we should actually be paying attention to such an old document. I’d definitely read and follow an update, though.
RFC 3986 Link >
The Wikipedia article on URI Link >